
作者:
OpenAI:我们已经在 ChatGPT 中实现了对插件的初步支持。插件是专门为语言模型设计的工具,以安全为核心原则,并帮助 ChatGPT 访问最新的信息,运行计算,或使用第三方服务。
根据我们的迭代部署理念,我们正在逐步推出 ChatGPT 中的插件,以便我们能够研究它们在现实世界中的使用、影响以及安全和协调方面的挑战 -- 为了实现我们的使命,我们必须做好这些工作。
自从我们推出 ChatGPT 以来,用户一直在要求使用插件(许多开发者也在尝试类似的想法),因为它们可以释放大量可能的用例。我们正从一小部分用户开始,并计划在我们了解到更多信息后,逐步推出更大规模的访问(针对插件开发者、ChatGPT 用户,以及在 alpha 期之后,希望将插件整合到他们产品中的 API 用户)。我们很高兴能建立一个塑造未来人类与人工智能互动模式的社区。
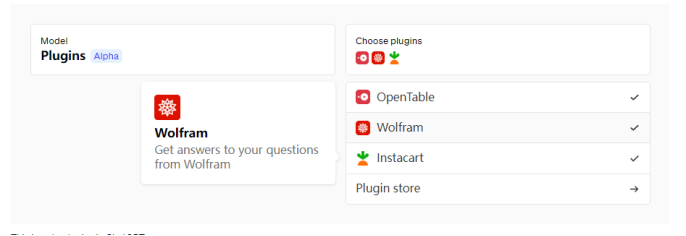
从我们的候选名单中被邀请的插件开发人员可以使用我们的文档来构建 ChatGPT 插件,然后在显示给语言模型的提示中列出启用的插件,以及指导模型如何使用每个插件的文档。首批插件由 Expedia、FiscalNote、Instacart、KAYAK、Klarna、Milo、OpenTable、Shopify、Slack、Speak、Wolfram 和 Zapier 创建。
我们自己也有两个插件,一个是网页浏览器,一个是代码解释器。我们还开源了一个知识库检索插件的代码,任何有信息的开发者都可以自行托管,以增强 ChatGPT 的功能。
今天,我们将开始向白名单上的用户和开发者提供该插件的 alpha 权限。虽然我们最初会优先考虑少数开发者和 ChatGPT Plus 用户,但我们计划随着时间的推移推出更大规模的访问。
概述
今天的语言模型,虽然对各种任务都很有用,但仍然是有限的。它们可以学习的唯一信息是它们的训练数据。这些信息可能是过时的,而且在各种应用中都是一刀切的。此外,语言模型唯一可以开箱即用的就是发出文本。这个文本可以包含有用的指令,但要真正遵循这些指令,你需要另一个过程。
虽然不是一个完美的比喻,但插件可以成为语言模型的“眼睛和耳朵”,让它们获得太新、太个人、太具体而无法包含在训练数据中的信息。为了响应用户的明确要求,插件也可以使语言模型代表其执行安全的、受限制的行动,从而提高系统的整体实用性。
我们期待开放标准的出现,以统一应用程序公开面向 AI 界面的方式。我们正在对这样一个标准进行早期尝试,正在寻找有兴趣与我们一起建设的开发者的反馈。
今天,我们开始逐步为 ChatGPT 用户启用我们早期合作者的现有插件,从 ChatGPT Plus 用户开始。另外,我们也开始允许开发人员为 ChatGPT 创建自己的插件。
在未来几个月,随着我们从部署中学习并继续改进我们的安全系统,我们将对这个协议进行迭代,我们计划让使用 OpenAI 模型的开发者将插件整合到他们自己的应用程序中,而不是 ChatGPT。
安全和更广泛的影响
将语言模型连接到外部工具,既带来了新的机遇,也带来了新的风险。
插件提供了解决与大型语言模型相关的各种挑战的潜力,包括“幻觉”,跟上最近的事件,以及(经许可)访问专有信息源。通过整合对外部数据的明确访问 -- 例如网上的最新信息、基于代码的计算或自定义插件检索的信息 -- 语言模型可以通过基于证据的参考来加强其反应。
这些参考资料不仅可以提高模型的效用,而且还可以使用户评估模型输出的可信度,并反复检查其准确性,从而有可能减轻与过度依赖有关的风险,正如我们最近在 GPT-4 系统卡中所讨论的。最后,插件的价值可能远远超出解决现有的限制,帮助用户完成各种新的用例,从浏览产品目录到预订航班或订购食物。
同时,风险是插件可能通过采取有害的或非预期的行动来增加安全挑战,增加那些会欺诈、误导或虐待他人的不良行为者的能力。通过增加可能的应用范围,插件可能会提高模型在新领域采取错误或不一致的行动所带来的负面影响的风险。从第一天起,这些因素就指导着我们的插件平台的发展,我们已经实施了一些保障措施。
我们已在内部并与外部合作者进行了红队测试练习(red-teaming exercises),发现了一些可能的相关情况。例如,我们的红队成员发现了插件的方法 -- 如果在没有保护措施的情况下发布,可以执行复杂的提示注入,发送欺诈性和垃圾邮件,绕过安全限制,或滥用发送到插件的信息。我们正在使用这些发现来告知设计安全缓解措施,以限制有风险的插件行为,并提高作为用户体验一部分的插件如何以及何时运作的透明度。我们还利用这些发现来决定逐步部署对插件的访问。
如果你对该领域的安全风险或缓解措施感兴趣,我们鼓励你参与我们的研究人员访问计划。我们还将邀请开发者和研究人员提交与插件相关的安全和能力评估,作为我们最近开源的 Evals 框架的一部分。
插件将可能产生广泛的社会影响。例如,我们最近发布了一份工作文件,发现可以使用工具的语言模型可能会比没有使用工具的语言模型产生更大的经济影响。更普遍的是,与其他研究人员的发现一致,我们预计当前的人工智能技术浪潮将对就业转型、转移和创造的速度产生很大影响。我们渴望与外部研究人员和我们的客户合作,研究这些影响。
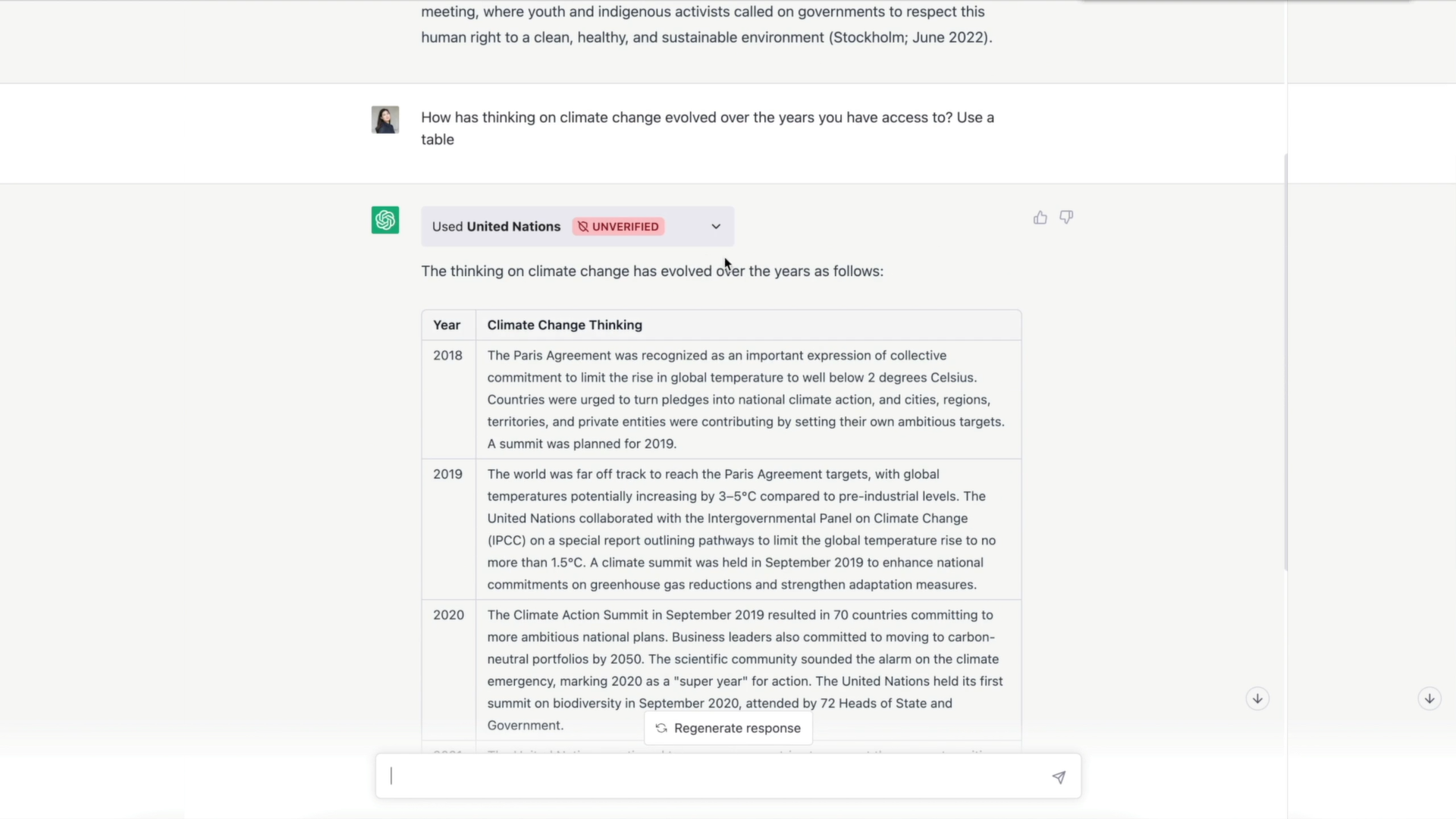
Browsing(Alpha 阶段)
一个知道何时及如何浏览互联网的实验性模型。
受过去工作(我们自己的 WebGPT,以及 GopherCite、BlenderBot2、LaMDA2 等)的激励,允许语言模型从互联网上读取信息,严格扩展了它们可以讨论的内容的数量,超越了训练语料库,扩展到了当前的新鲜信息。
下面是 ChatGPT 用户的 Browsing 体验的一个例子。在此之前,若提出这些问题,模型会礼貌地指出它的训练数据没有包含足够的信息来让它回答。在这个例子中,ChatGPT 检索关于最新奥斯卡奖的最新信息,然后执行我们现在熟悉的 ChatGPT 诗歌表演,这是 Browsing 可以成为附加体验的一种方式。
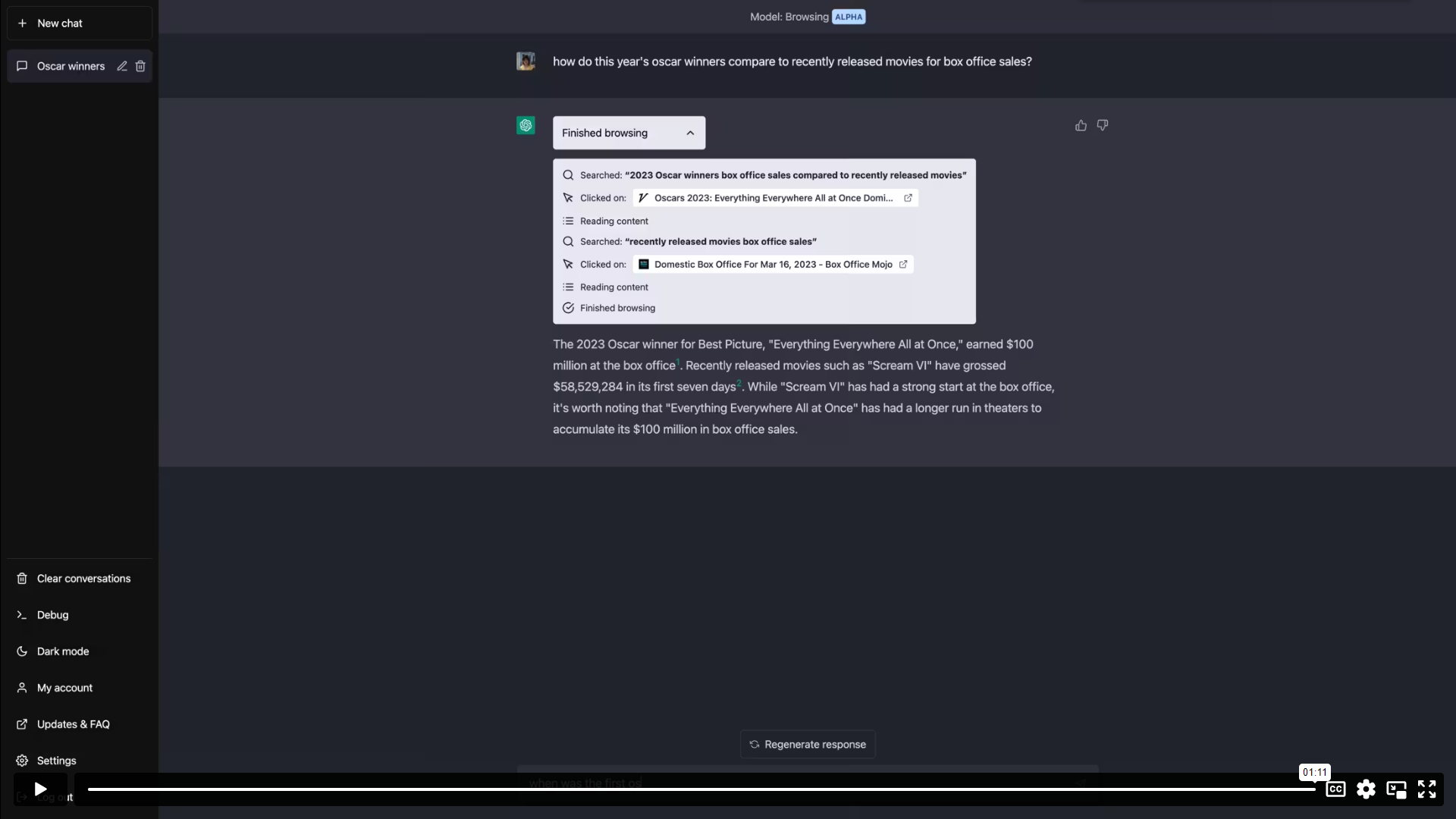
除了为终端用户提供明显的效用外,我们认为使语言和聊天模型能够进行彻底和可解释的研究,在可扩展对齐方面有着令人兴奋的前景。
安全考虑
我们已经创建了一个网络 Browsing 插件,允许语言模型访问网络浏览器,其设计优先考虑安全和作为网络良好公民来运作。该插件的基于文本的网络浏览器被限制在发出 GET 请求,这减少了(但没有消除)某些类别的安全风险。这使得 Browing 插件在检索信息方面很有用,但不包括”事务性“操作,如表单提交,因为这些操作涉及更多的安全和保障问题。
Browsing 使用 Bing 搜索 API 从网上检索内容。因此,我们继承了微软在以下方面的大量工作:(1)信息来源的可靠性和真实性;(2)防止检索有问题内容的”安全模式“。该插件在一个独立的服务中运行,因此 ChatGPT 的 browsing 活动与我们基础设施的其他部分分开。
为了尊重内容创作者并遵守网络规范,我们的浏览器插件的用户代理标记是 ChatGPT-User,并被配置为尊重网站的 robot.txt 文件。这可能偶尔会导致”click failed“的消息,这表明该插件正在尊重网站的指示,以避免抓取它。该用户代理仅用于代表 ChatGPT 用户采取直接行动,不用于以任何自动方式抓取网络。我们也已经公布了我们的 IP 出口范围。此外,我们还采取了限制速率的措施,以避免向网站发送过多的流量。
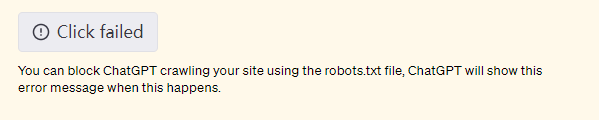
你可以使用 robots.txt 文件阻止 ChatGPT 爬取你的网站,这时 ChatGPT 会显示这个错误消息。
我们的 Browsing 插件会显示访问过的网站,并在 ChatGPT 的回复中引用其来源。这种增加的透明度有助于用户验证模型反应的准确性,同时也将功劳归于内容创造者。我们认为这是一种与网络交互的新方法,并欢迎对其他方法的反馈,以推动流量回到源头,并增加生态系统的整体健康。
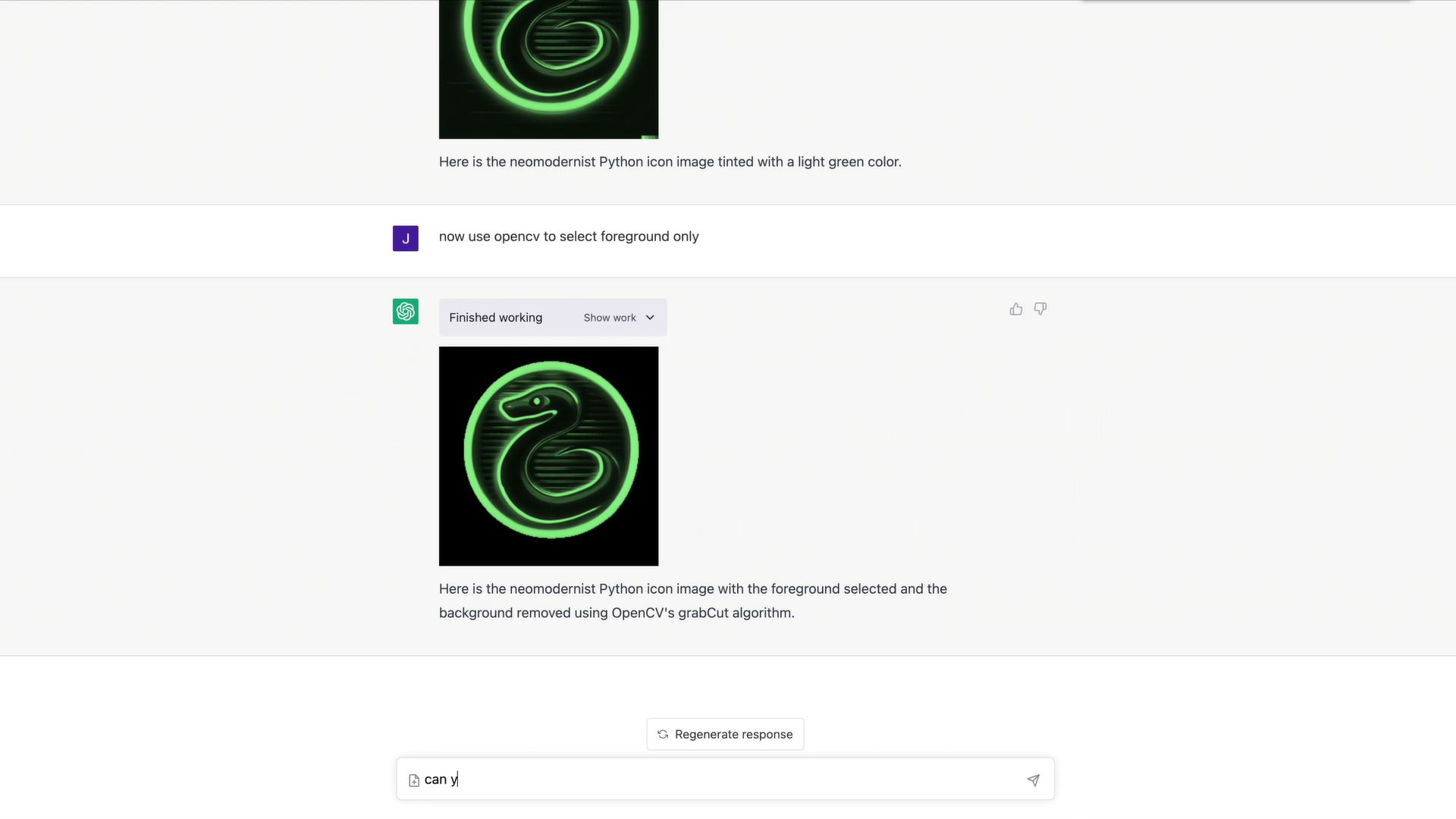
代码解释器(Alpha 阶段)
一个实验性的 ChatGPT 模型,可以使用 Python,处理上传和下载。
我们为我们的模型提供了一个在沙箱、防火墙执行环境中运作的 Python 解释器,以及一些临时的磁盘空间。由我们的解释器插件运行的代码在一个持久的会话中被评估,该会话在聊天对话期间是有效的(设有上限时间),随后的调用可以建立在彼此之上。我们支持将文件上传到当前的对话工作区并下载你的工作结果。
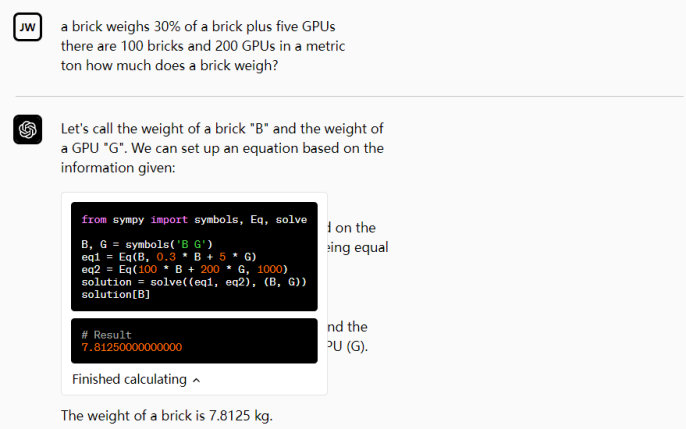
我们希望我们的模型能够使用它们的编程技能,为我们的计算机的最基本功能提供一个更自然的接口。让一个非常热心的初级程序员以指尖的速度工作,可以使全新的工作流程变得轻松和高效,并向新受众开放编程的好处。
从我们最初的用户研究中,我们已经确定了使用代码解释器特别有用的用例:
解决数学问题,包括定量和定性的数学问题
进行数据分析和可视化
在不同格式之间转换文件
我们邀请用户尝试代码解释器集成并发现了其他有用的任务。
安全考虑
将我们的模型连接到编程语言解释器的主要考虑因素是适当的沙盒执行,以便人工智能生成的代码不会在现实世界中产生意想不到的副作用。我们在一个安全的环境中执行代码,并使用严格的网络控制来防止外部互联网对已执行代码的访问。此外,我们还对每个会话设置了资源限制。禁用互联网访问限制了我们的代码沙盒的功能,但我们相信这是正确的初始权衡。第三方插件被设计为一种安全第一的方法,将我们的模型与外部世界连接起来。
检索
开源的检索插件使 ChatGPT 能够访问个人或组织的信息源(经许可)。它允许用户通过提问或用自然语言表达需求,从他们的数据源中获得最相关的文件片段,如文件、笔记、电子邮件或公共文档。
作为一个开源和自我托管的解决方案,开发者可以部署自己的插件版本,并在 ChatGPT 注册。该插件利用 OpenAI 嵌入,并允许开发者选择一个矢量数据库(Milvus、Pinecone、Qdrant、Redis、Weaviate 或 Zilliz)来索引和搜索文档。信息源可以使用 webhooks 与数据库同步。
开始着手可先访问检索插件库。
安全考虑
检索插件允许 ChatGPT 搜索一个矢量数据库的内容,并将最佳结果添加到 ChatGPT 会话中。这意味着它没有任何外部影响,主要风险是数据授权和隐私。开发者应该只在他们的检索插件中添加被授权使用并可以在用户的 ChatGPT 会话中分享的内容。
第三方插件(Alpha 阶段)
一个实验性的模型,知道何时以及如何使用插件。
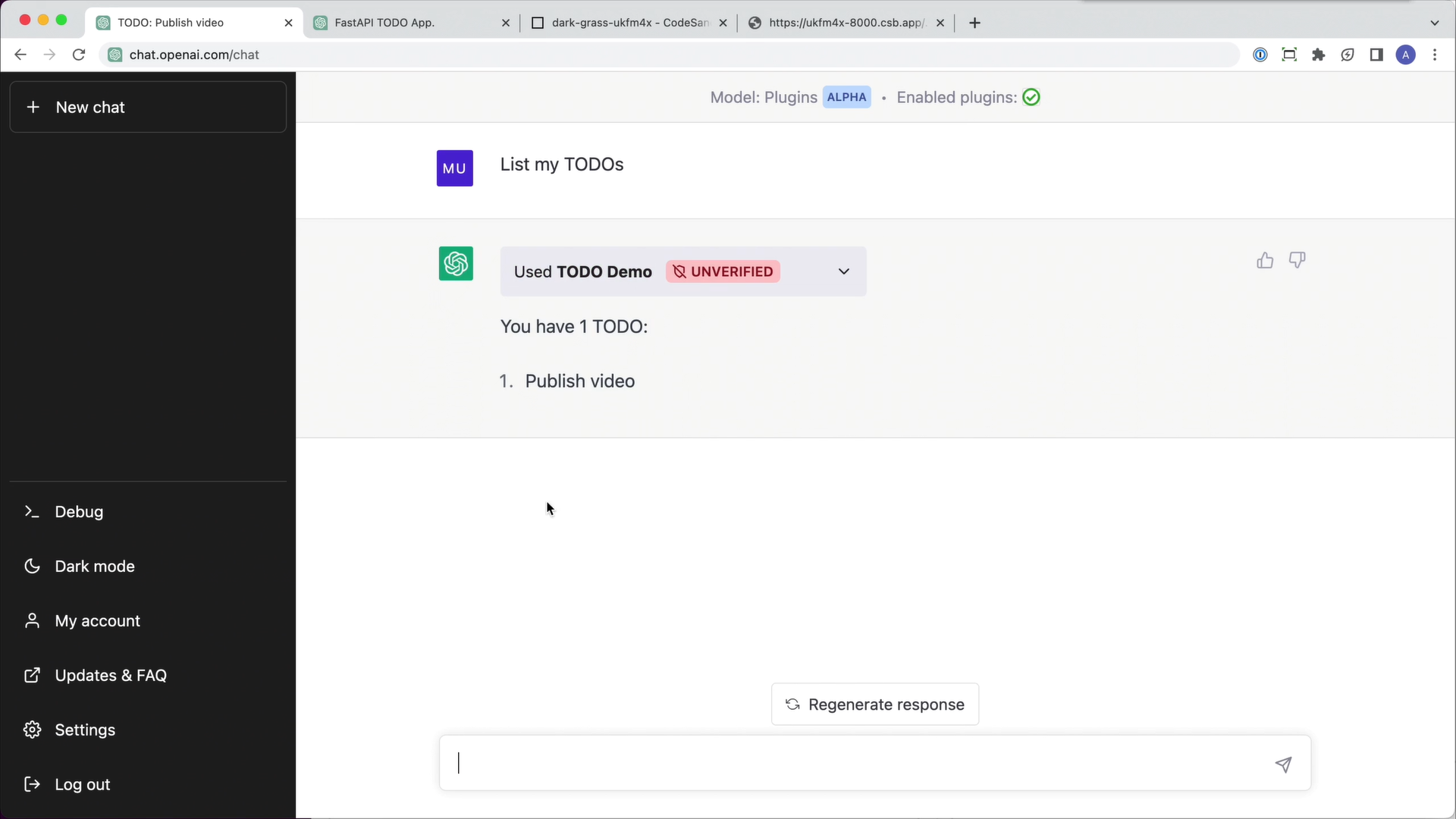
ChatGPT 中的第三方插件
第三方插件由一个清单文件描述,其中包括机器可读的插件功能和如何调用它们的描述,以及面向用户的文档。

一个用于管理待办事项的插件的清单文件示例
创建插件的步骤是:
建立一个带有你希望语言模型调用的端点的 API(这可以是一个新的 API,一个现有的 API,或者一个专门为 LLM 设计的现有 API 包)。
创建一个记录你的 API 的 OpenAPI 规范,以及一个链接到 OpenAPI 规范并包括一些插件特定元数据的清单文件。
在 chat.openai.com 上开始对话时,用户可以选择他们希望启用的第三方插件。关于启用的插件的文档会作为对话上下文的一部分显示给语言模型,使模型能够根据需要调用适当的插件 API 来实现用户的意图。目前,插件是为调用后端 API 而设计的,但我们也在探索可以调用客户端 API 的插件。

展望未来
我们正在努力开发插件,并把它们带给更多的受众。我们有很多东西需要学习,在大家的帮助下,我们希望建立一个既有用又安全的东西。
注:文中涉及多处视频演示,可参看原文。
本文为作者投稿,不代表本站立场,转载联系作者并注明出处:蜂鸟财经https://fnfin.cn/news/184.html
